最近两个月,DeepSeek无疑是股市上最靓的仔。
虽然DeepSeek并没有上市,但江湖上满是他的传说——
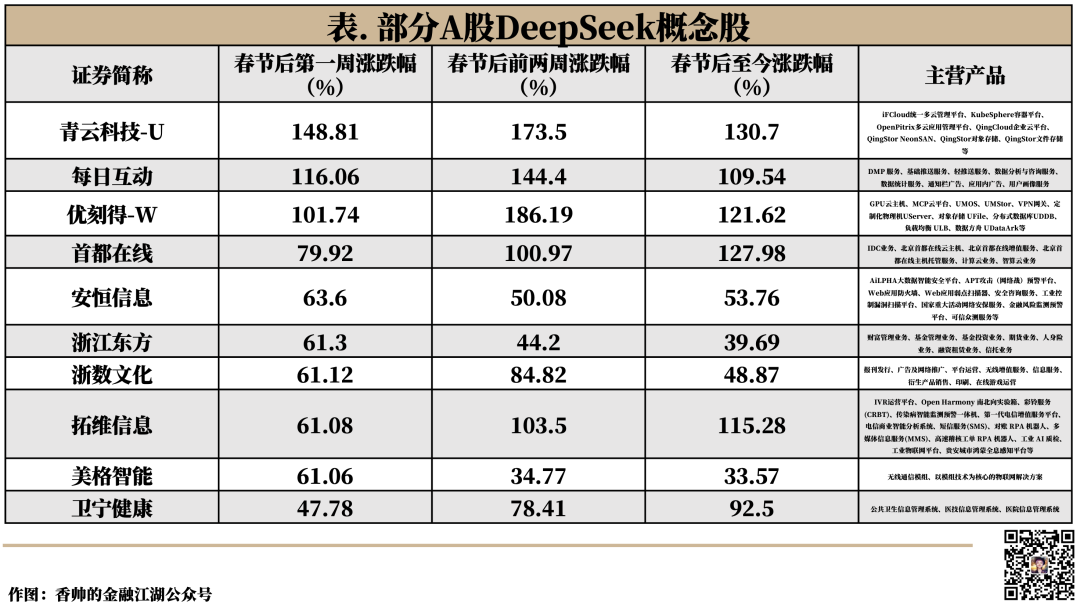
A股市场冒出一批DeepSeek概念股,自春节假期结束以来,平均上涨42%,涨幅最高的涨了130%以上;
港股市场上,DeepSeek还惠及“友商”阿里和腾讯等等,中国资产重估叙事大行其道;
美股市场上,DeepSeek也让美国科技股牛市摔了个跟头,尤其是动摇了“英伟达信仰”——英伟达股价在1月27日暴跌17%,创下美国企业史上最大单日市值蒸发记录。虽然后来曾经一度收复失地,但市场仍在担忧DeepSeek会改变英伟达叙事。
显然,DeepSeek对整个市场带来了巨大冲击,这使我们必须思考三个问题:
AI生态怎么走?
英伟达估值逻辑发生什么变化?
中国科技股估值逻辑发生什么变化?
01
AI生态怎么走?
虽然DeekSeek带来了很多不确定性,但有一条逻辑是具备确定性的:DeekSeek代表着AI大模型的竞争会进一步激化,AI应用也将迎来爆发式增长。
首先,我们来看AI大模型的竞争。
在1月的最后一周,DeepSeek-R1发布几天后迎来了爆发,在没有任何广告投放的情况下,7天完成了1亿用户的增长。
DeekSeek为什么这么火?
有两个重要特质,第一,低成本。DeepSeek-V3仅使用了2048块英伟达H800 GPU,耗费了557.6万美元就完成了训练,相比之下,Anthropic CEO曾透露,Claude3.5 Sonnet训练成本在数千万美元(cost a few $10M's to train)。也就是说,DeepSeek把训练成本打到了海外同行的1/10。
第二,开源。DeepSeek几乎将其所有研究成果都直接开源,与世界分享其技术路线。我并不懂DeepSeek的底层路线,引用峰瑞科技组的话来说,就是“DeepSeek第一次真正公开了用强化学习(Reinforcement Learning,简称RL)做推理模型的可能路径。强化学习是一种机器学习方法,通过智能体(Agent)与环境(Environment)的交互,学习最佳策略”。
低成本和开源,直接冲击了美国科技七巨头(Mag 7)在大模型方面的垄断地位。
在2023年底写作的《钱从哪里来》中,我们曾经讲过——
“大语言模型的进入门槛高到惊人,单单这一条就足以阻吓小型创业公司。
大语言模型训练的“烧钱”程度真的超出想象。以GPT-4.0为例,要达到训练所需的算力,使用在云端的A100 GPU,单次训练的成本将达到约6300万美元,另外这种GPU每块价值1万美元,需要2.5万枚,就是2.5亿美元;现在正在训练的GPT-5,需要5万块GPU,价值接近20亿美元,这还只是开局的基础配置。”
但是,这个逻辑变了。
大型科技公司依旧拥有较深的护城河,在数据、人才、算法和商业模式等方面拥有更多优势,但是,护城河的裂缝也在出现,更多的公司在想,是不是“我上我也行”?
DeekSeek之后,最近一个月我们又看到了更多大模型的快速迭代:
2月6日,OpenAI宣布全面开放无门槛的ChatGPT搜索功能,用户无需注册即可使用。
2月7日,OpenAI宣布放开o3mini实时思维链,ChatGPT的免费和付费用户都能看到推理过程。
2月18日,马斯克的xAI发布了更新版Grok 3大模型。在直播的现场演示中,Grok 3在数学、科学和编程基准测试中,击败了包括DeepSeek的V3模型和GPT-4o在内的多个模型。
3月6日,阿里Qwen团队发布了QwQ-32B大语言模型,这款模型拥有320亿参数,在性能上能够与参数量高达6710亿的DeepSeek-R1相媲美。
2月初,法国的创业公司Mistral AI推出了 Le Chat,训练成本也仅为OpenAI的1/5,而且推理速度比ChatGPT 快13倍,并且和Deepseek一样完全开源完全免费,下载量迅速攀升成为市场第三。
3月7日,Mistral AI又宣布“我们近期将发布非常强大的模型,该模型将超越 DeepSeek。”其创始人说,DeepSeek是开源领域的贡献者而非竞争对手,并认为开源模式鼓励企业相互借鉴,形成良性竞争,推动AI技术的整体发展。
可以说群雄并起,“晋西北打成一锅粥”了。
但是,百花齐放的景象,对公司股价来讲并不是好消息。
在这么卷的市场竞争之下,AI大模型大概率只能搞低价策略,而且会经历一轮又一轮血腥厮杀,直至留下两三个巨头。大语言模型就像操作系统,具有很高的通用性和规模效应:大语言模型每增加一个用户,边际成本递减,而用户数据量增加,还可能带来大语言模型能力提升和生态繁荣,所以,一定是强者愈强,最终少数寡头占领市场。
最终究竟鹿死谁手?谁也不知道。
因此,AI大模型领域也许注定会是伟大行业,平庸投资。
2024年,科技七巨头(Mag 7)的AI资本支出越大,投资者越兴奋,而现在,这个叙事正在被动摇,华尔街越来越想看到现金流——
近日,微软、Meta、谷歌、亚马逊先后发布财报,并披露对2025年的指引。四家巨头仍然发布了持续上涨的“烧钱”计划,比如亚马逊表示,预计2025年的资本支出将从2024年的830亿美元左右增加至1000亿美元。但是,股票市场的表现并不尽如人意,整个2月,微软、谷歌、亚马逊股价都下跌了10%以上。
我们再来看AI应用,未来可能会涌现更多的创业和投资机会。
在下一场数字生态的进化中,大语言模型是土壤。任何一片土地都需要有千万棵松树参天立地,才能让女萝、菟丝托付,才能吸引虫鸟,“缠绵成一家”。所以生态要形成,必须有大量垂直领域的应用开发涌入。
在生态建设方面,ChatGPT早已先行一步。早在2023年11月6日,OpenAI在旧金山举办了首届ChatGPT开发者大会(DevDay),又更进一步提出了定制GPT工具(GPTs)的概念,也就是说,用户可以基于ChatGPT创建自己的AI应用。到目前,全网已经涌现出300万个GPTs。
但国内与ChatGPT生态几乎无缘,因此,DeepSeek对国内AI产业最大的冲击是,显著降低了AI应用门槛。就像安卓系统开源推动智能手机普及那样,这次技术开放让更多开发者能直接借鉴或使用现成模型,大大节省研发成本。随着使用成本降低,AI应用场景将迎来爆发式增长。这种"降价-普及-需求激增"的良性循环,的确有希望刺激国内AI和芯片产业的长期发展。
李彦宏曾说:“大模型时代,最大的创业机会在应用。移动互联网时代,操作系统其实没几个,最成功的是微信、抖音、淘宝这些应用。未来10年,可能诞生10倍价值于它们的机会。”
虽然百度的AI大模型和AI应用做得不温不火,但李彦宏这段话大概率是对的。
02
英伟达叙事?
Deepseek发布之后,股价波动最大的就是英伟达。1月27日,美股龙头英伟达股票暴跌近17%,市值蒸发5927亿美元(约合4.3万亿人民币),创下美股史上最大单日市值下跌纪录。
但是,我们冷静下来思考,Deepseek对英伟达而言,到底是好消息,还是坏消息?
我们的回答是好坏参半。中长期逻辑上可能是好消息,但短期逻辑上更多是坏消息。
先说短期逻辑。英伟达芯片归根结底还是资本品,也就是说周期性会比较强。
在过去两年,AI火热的周期,科技股大量烧钱投资AI基础设施,英伟达的业绩猛涨,股市投资者也总是倾向于线性外推,股价也会加速上涨。比如2024年,Big Five的股价平均涨幅是38%,而英伟达上涨了171%。
但是,如果行情不好(不管是AI信仰退潮,还是经济衰退),科技股开始放缓AI资本支出增速,或者更多地专注于利用现有的英伟达芯片,那么股市投资者也会调低业绩预期,英伟达股价也有可能加速下跌。
不过,在中长期逻辑上,DeepSeek这样开源的推理AI模型,正在加剧大模型领域竞争,也给了AI应用开发以更广阔的空间,注定会消耗更多计算量。这对英伟达来说,无疑是好消息。
打个不太确切的比方,在汽车萌芽期,有款汽车大大降低了耗油量,最终会导致原油价格下跌吗?大概率不会。因为汽车耗油量下降,让普通人更能买得起车,创造了更多汽车需求,还是会提高全世界对原油的需求。
在2月底的英伟达财报会上,黄仁勋也从基础设施和资本支出的长期角度勾勒了一个宏大图景:现在软件已经从在CPU上运行的手工编码,转变为在GPU和加速计算系统上运行的基于机器学习和AI的软件)。AI将成为数据中心的主要工作者,数据中心的资本投资需求将大增。
不过,在更遥远的未来,英伟达最大的噩梦可能是未来的大语音模型选择绕开英伟达CUDA生态。
这个噩梦是否会成真?其实我作为非专业人士没什么发言权,我选择了咨询DeekSeek和ChatGPT,供大家参考。
Deepseek说:
短期(3-5年):
CUDA仍为主流,但部分场景(边缘计算、特定云服务)出现替代方案。
混合生态(CUDA+其他硬件)成为过渡方案,如使用Triton编写跨平台内核。
中长期(5-10年):
若AMD/Intel/开源社区持续投入,可能出现“多极化”生态,但CUDA份额逐步下降。
专用领域(如小模型推理、端侧AI)优先脱离CUDA依赖。
ChatGPT说:
未来大语言模型绕开英伟达CUDA生态是有可能的,但需要以下几个条件的成熟与配合:
替代硬件平台的发展:如AMD GPU(ROCm)、Google TPU、华为昇腾等正逐步崛起。
跨平台软件生态:开源计算框架(例如OpenCL、Vulkan Compute、oneAPI)和优化库需同步跟进。
市场需求与生态完善:市场对开放标准和多样化生态的需求将推动替代方案的发展,但目前CUDA因其成熟度和资源优势仍占主导地位。
综合来看,短期内替代CUDA的难度较大,但长期来看,多平台和开放标准方案有望逐步实现。
03
中国资产重估叙事
DeekSeek推出之后,反应最热烈的就是港股和A股。春节后以来,恒生科技指数和科创50指数分别上涨了28%和14%。
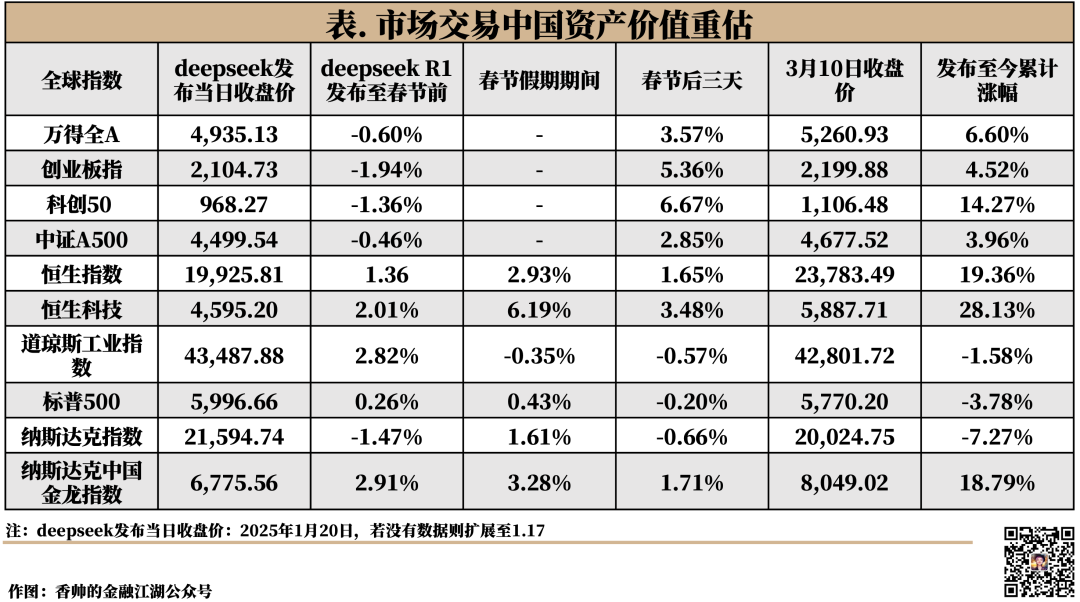
对中国市场而言,DeepSeek的成功最大的意义在于提振了市场信心。
DeepSeek本身是否能够持续成功,这个问题还有待探讨,或许也并不重要。但它释放了一个很重要的信号:在美国的封锁之下,中国科技企业还有能力发展AI,并以低成本赶上美国同行。
在过去很长时间内,中国科技股被排除在“AI叙事”之外。首先是因为美国多方封锁,其次也是中国企业没有拿出令人印象深刻的AI产品。再次,中国平台监管政策和消费市场不景气,也拖累了科技股的表现。
而现在,国内外投资者开始重新评估中国科技企业的技术潜力和市场潜力。
高盛、摩根大通、瑞银、德意志银行、摩根士丹利等国际大行纷纷在研报中“看多中国资产”,一场围绕中国资产的“价值重估”浪潮正席卷市场。
瑞银证券发布报告《中国科技七姐妹:新工业革命领航者》,首次提出对标美股“七巨头”的中国科技企业矩阵——腾讯、阿里、字节跳动、华为、比亚迪、宁德时代、京东,认为这批企业将在全球第四次工业革命中扮演关键角色。
德意志银行2月5日发布策略报告《中国吞噬世界:中国的“斯普特尼克时刻”》(China eats the World:China's, not Al's, Sputnik moment),认为中国资产面临重估,2025年是中国的“斯普特尼克时刻”。预计中国股票的“估值折价”将消失,盈利能力可能因政策支持消费和金融自由化而超出预期。港股/A股的牛市始于2024年,预计会在中期内超过之前的高点。
2月17日,高盛发布报告称,DeepSeek-R1的出现,以及其它最近推出的具有全球竞争力和成本效益的中国人工智能模型,改变了中国科技的叙事,提升了投资者对人工智能增长和经济利益的乐观预期。高盛还构建了一个包含6个主题板块的中国AI股票投资框架,包括半导体、基础设施、数据与云计算、软件与应用、收入增长型和生产力提升型等板块。高盛将MSCI中国/沪深300的目标价提高到85和4700,意味着12个月的潜在上涨空间分别为16%和19%。
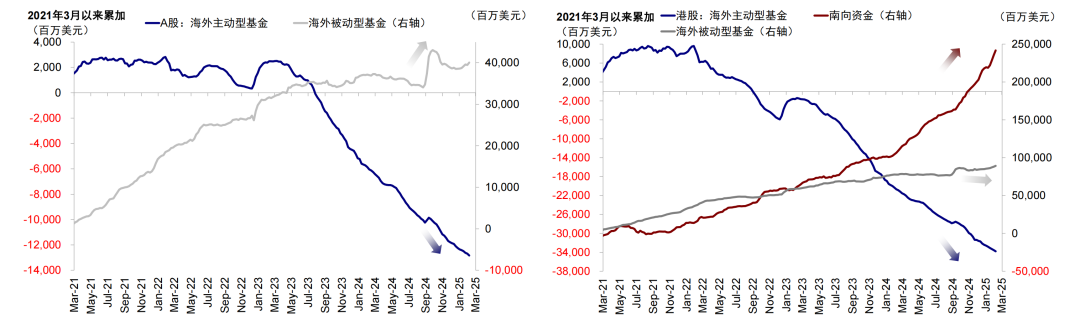
但是除了看外资说了什么,更重要的是外资做了什么。
如果你看一下外资的资金流动,你会发现,海外主动型基金仍在持续流出A股和港股。
而且,A股很多所谓的DeepSeek概念股,与DeekSeek的关联度并不高,接入DeekSeek的动作能否转化为利润提升,还有待观察。
情绪刺激带来的上涨,只能说是短期叙事,更长久的涨幅还要来自真金白银的业绩提升。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}